


How Avalanche uses Machine Learning to make photo apps speak the same language
The language of image adjustments
Avalanche promises its users that it will preserve the visual aspect of the migrated images by applying some clever algorithms to derive the adjustments in Lightroom (for example) from the adjustments in Aperture.
Because every app has its own RAW engine, and its own way to name and dimension the settings, it is not possible to simply take the value of a specific setting in Aperture – say, a WB temperature – and apply it in Lightroom. The results would be totally off.
Let’s look at a simple example to illustrate how machine learning works in Avalanche. To obtain the same visual aspect in both Aperture and Lightroom, the values to apply to both the WB temperature and exposure are completely unrelated.

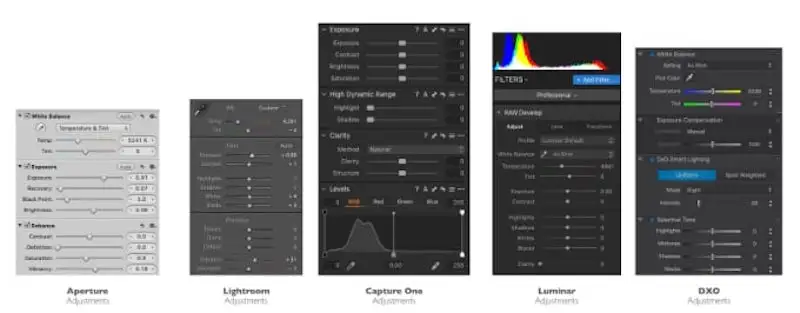
- In Aperture you’ll find adjustments called : Exposure, Recovery, BlackPoint, Brightness, Definition, Highlights, Shadows, Mid Contrast.
- In Lightroom, they are called : Exposure, Blacks, Whites, … There is no Brightness, no Midtones but a Texture adjustment.
- In CaptureOne, they are called : Exposure, Highlights, Shadows,… There is a Brightness adjustment but no Midtones.
- In DXO, the list is even more different due to the specific capabilities of the software.
Sometimes, some adjustments don’t even exist in the target application. One example is the Skin tone White Balance setting in Aperture. How to transfer the settings of an image using that specific white balance parameter to Lightroom where this concept does not exist ?
Enter Machine Learning, or ML for short.

The idea behind ML is to learn from a set of images that have been adjusted in Aperture and Lightroom, what are the “functions” to apply to the set of parameters in Aperture, in order to find, one by one, the value of each parameter in Lightroom.
Using some mathematical language, let us assume that the set of parameters in source application are called (x, x2,,…..,xn) and the target parameters are called (y1,y2,….,ym). We try to find the function fi (i=1…m) that lets us compute hi = fi (x, x2,,…..,xn) and minimizes the error between hi and yi for all our images. In other words, we try to find functions that predict the value of any parameter yi in the target app from the input parameters in the source app.
There is no need to find the explicit formula for this function. Machine Learning gives us the ability to create a model that contains the information about those functions. For Avalanche, we train the model by exposing it to a large set of input and output images that have been carefully prepared.
At the end of the training, the model is able to predict the results for images that it has never seen.
The model is trained on a subset of the images – 80% of the images are used for that- and tested on the remaining 20%. The accuracy of the prediction in Avalanche is assessed and when anomalies are detected, we try to understand the cause, work on the data, or add more images if we think that the dataset is not sampling all the possibilities well enough.
The key for success is of course to have as many images as possible that cover as many situations as possible. We also shift the settings on some images to explore variations.
In the case of Lightroom, the list of parameters we aim to predict contains the following: WhiteBalance temperature and tint, exposure, contrast, highlights, shadows, whites, blacks, saturation, vibrance. Color toning.
For Avalanche, we use different techniques for curves and for parameters that are more complex (noise, texture, vignetting)
How you can help training our models
From the above, it is obvious that gathering as much quality data as possible is the key to getting very good adjustment migration results.
Therefore, we would love to get contributions from you if you feel like sending a few pictures that have carefully been adjusted in both the source and the target application. In the case of the current version of Avalanche, this translates into :
creating an Aperture catalog with some images and adjusting them the way you would do it normally. Using images requiring some dramatic adjustments can be very useful to sample the edges of our parameter space.
creating a Lightroom catalog with the same images and adjusting the images in order to get ‘exactly’ the same visual aspect (color, exposure, toning, …) in both programs.
sending us the catalogs using WeTransfer.
We will only use the images for our Machine Learning algorithm.
Don’t hesitate to contact us if you need more details.






